
Nexus Data Hive
将海量原始测量数据,转化为设计到量产的决策依据。
Nexus Data Hive 作为 Nexus 产品系列的核心产品,是处理光子学测量复杂数据的利器。
它能将杂乱的原始数据转化为清晰可用的信息,确保您的器件库与晶圆厂(Fab)的实际物理状态完美对齐,助您全面掌控光子集成电路(PIC)的数据流。
About 
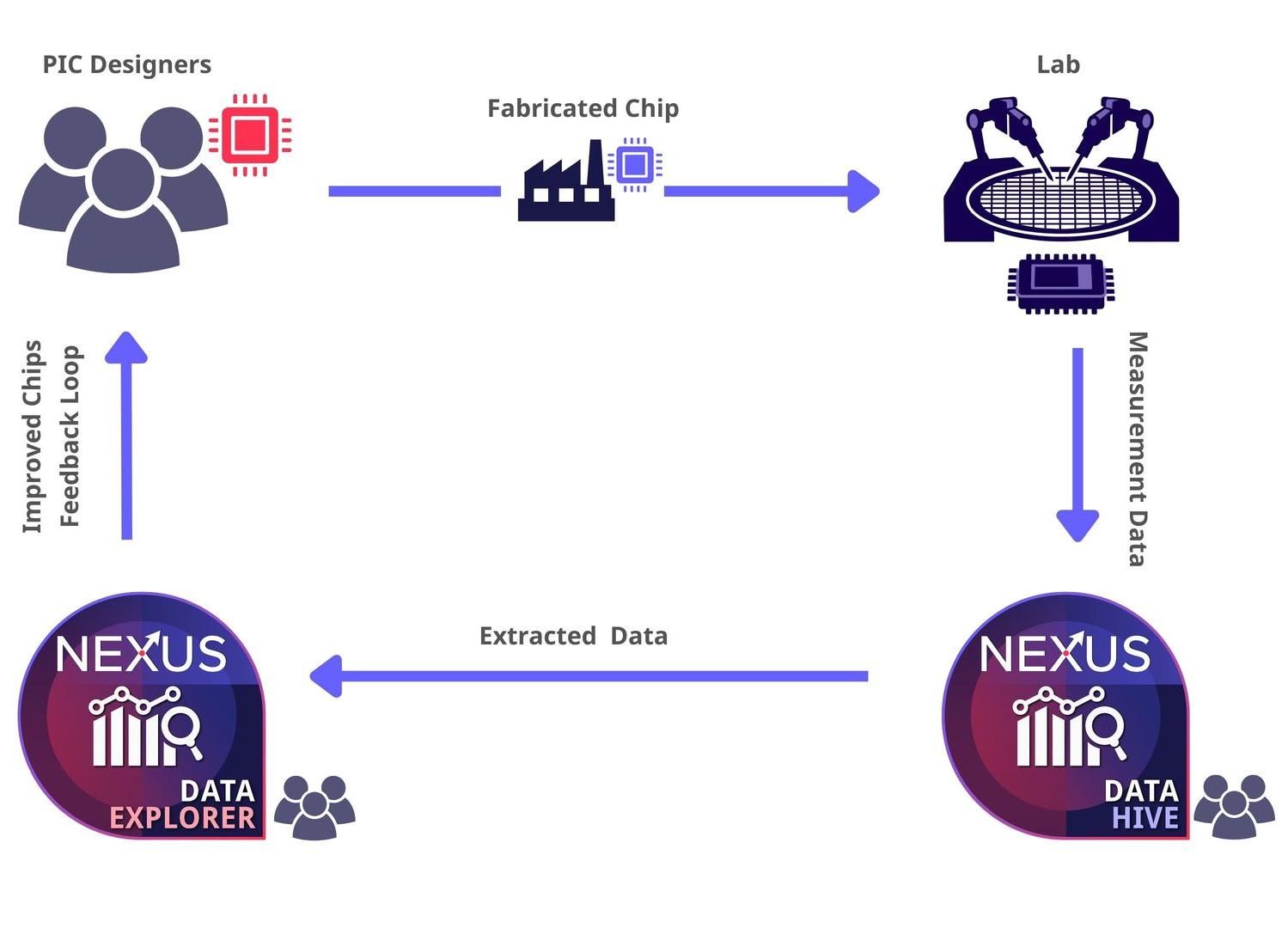
Nexus 是我们的数据分析产品系列,包含 Nexus Data Hive 和 Nexus Data Explorer 两大核心产品。 它为基于实测数据的验证工作提供了标准化的基础设施,帮助您摆脱零散脚本和手动数据处理的束缚,迈向完全集成、自动化的数据处理和决策分析。
About Nexus Data Hive
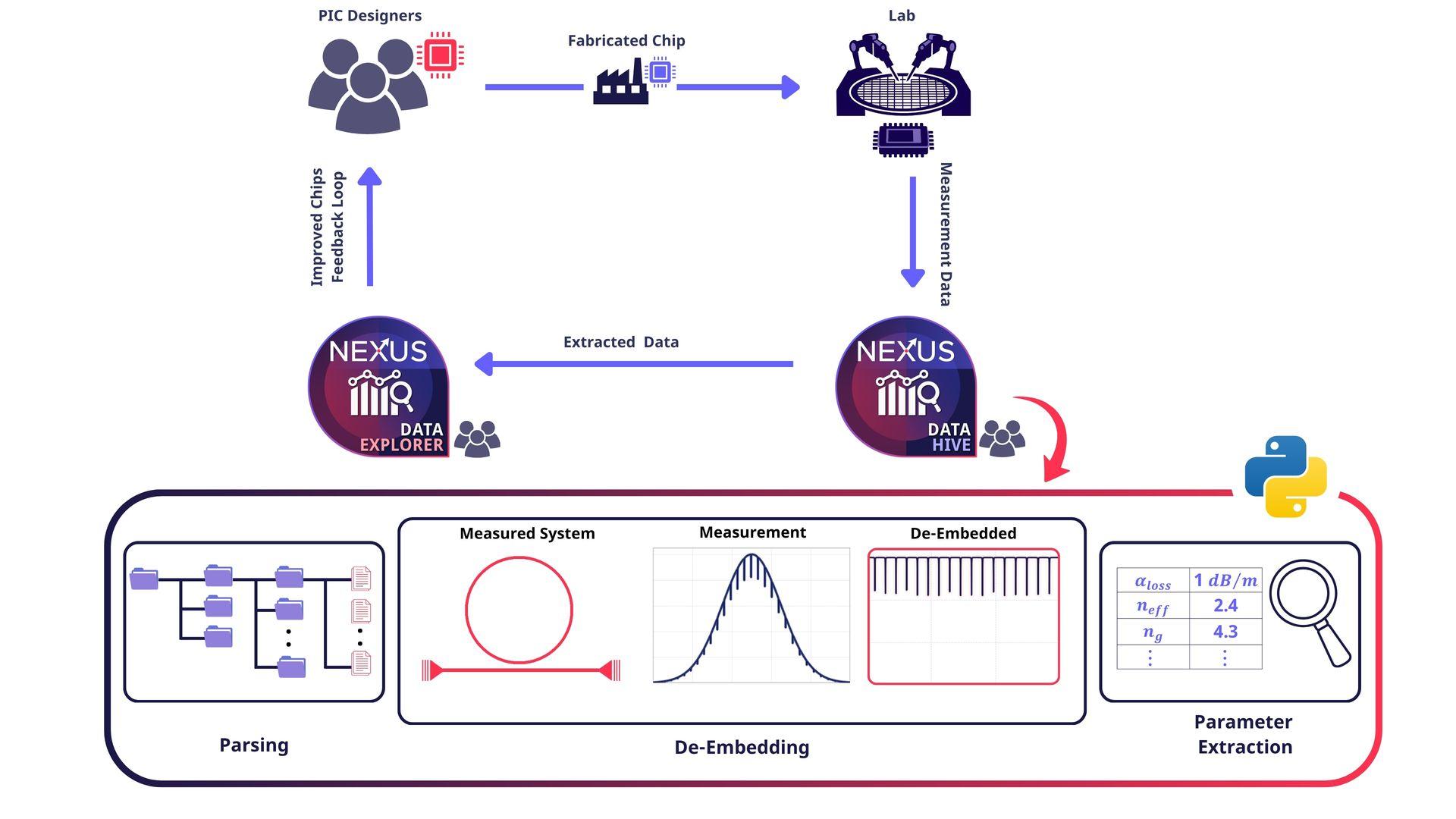
Nexus Data Hive 是一个基于服务器的测量数据管道与管理平台,面向光子学和微电子领域,服务于晶圆厂、IDM、中试线以及相关设计团队或公司。 它能本地集中存储和管理海量测试数据,通过策略设置驱动自动化工作流完成相关分析; 通过搭建起原始测试仪器与结构化数据库之间的桥梁,它能够从测量数据中自动提取测试键(Testkey)结果与性能指标。
Hive 大幅缩短数据分析、良率提升和模型验证的时间,减少流片间隔以提升开发效率。 它支持本地服务器部署,充分保障数据安全。团队可以在高性能环境中,用标准化的 Python 语言完成解析、去嵌入、参数提取等数据处理任务。
Nexus Data Hive 为硅基验证打造了一套标准化基础设施,帮您把海量原始测量数据,转化为设计到量产的决策依据,协同优化设计流程与晶圆厂(Fab)工艺。
核心功能
- 本地部署基础设施:完全部署在本地服务器或私有云上,支持容器化扩展。在保障绝对数据主权的同时,能够轻松应对高并发数据接入与大规模存储吞吐。
- 自动化分层元数据解析:自动提取非结构化的测试表头,将其映射为标准化的、可搜索的层级结构:批次 → 晶圆 → 芯片 → 测试键,并附带精确的执行时间戳。
- 算法去嵌入:提供系统化的工作流程,自动消除光纤、光栅耦合器和电探针引入的寄生损耗和插入损耗,同时支持用户自定义去嵌入脚本。
- 自动化光子学参数提取:
- 光学指标: 编写脚本,进行曲线拟合,提取光学损耗、有效折射率、中心波长和品质因子。
- 电学指标:编写脚本,提取光电二极管(PD)的 I-V 曲线、暗电流和击穿电压等参数。
核心优势
- 大幅提高数据处理效率:
自动化处理大规模光子学测量数据,支持即时反馈与交互。 - 数据不再打架:
标准化提取和清洗测量数据流程,为统计分析与工艺监控做准备。 - 促进团队协作:通过本地部署(On-premises)实现多团队协同。集中式部署消除了本地 SSD 存储容量的限制,并免去了本地 Python 环境配置与管理的繁琐过程。
如果你感兴趣或仍有疑问,欢迎: